
Data architectuur
Gemeenschappelijke taal
Wij zijn van mening dat het in een data-centrische organisatie essentieel is om een gemeenschappelijke taal (semantisch model of ontologie) te hanteren: een taal zonder homoniemen, synoniemen en ambiguïteit. Een taal dus waarin een attribuut met een bepaalde betekenis slechts één keer voorkomt en waarin elk attribuut is voorzien van een duidelijke, eenduidige definitie.
Daarnaast is het cruciaal dat de relaties tussen de verschillende attributen betekenisvol zijn en rijk aan semantiek. Deze taal is implementatie-onafhankelijk en beschrijft op een uniforme manier de data van de betreffende organisatie.
De noodzaak hiervan hebben we al besproken in het hoofdstuk over metadata. De rol van metadata wordt steeds belangrijker. Waar metadata vroeger vaak als secundair werd gezien — omdat men sterk leunde op de kennis van medewerkers — zien we dat computers steeds meer taken overnemen. Dat betekent dat zij de taal van de business moeten kunnen begrijpen.
We zullen hierop terugkomen en met voorbeelden laten zien hoe metadata in de praktijk van waarde is.
Voorbeeld beschrijving in UML
Class-diagrammen volgens de UML-methode worden al jarenlang gebruikt om datadomeinen te beschrijven. Wij beschouwen dit nog steeds als een uitstekende methode. Wat we echter vaak zien, is dat het modelleren stopt bij classes, attributen en relaties, terwijl de rollen van die relaties zelden worden gespecificeerd. Ook ontbreekt regelmatig een duidelijke definitie bij een class, attribuut of relatie — terwijl dat, zoals we eerder betoogden, juist van essentieel belang is.
Een ander praktijkprobleem is dat er vaak te abstract wordt gemodelleerd, met het oog op een generieke implementatie. Dit leidt tot een verlies aan semantiek, wat het moeilijker maakt om data eenduidig te interpreteren. We zullen dit later met een voorbeeld verder toelichten.
Een semantisch rijk UML-model vormt een uitstekende basis voor het ontwikkelen van een data-centrische organisatie. We spreken bewust van een ‘basis’, omdat — zoals eerder uitgelegd bij metadata — het gaat om álle data binnen een organisatie. De beschrijving van domeindata vormt hiervan slechts een onderdeel. Hier komen we later nog op terug.
Onderstaand UML-model is een voorbeeld van een beschrijving van domeindata. Het gaat hierbij niet zozeer om de inhoud — daar kunnen we van alles van vinden — maar om de patronen en de rijkheid aan semantiek. Deze semantiek zal ons straks ondersteunen wanneer we de metadata inzetten in combinatie met generatieve AI.
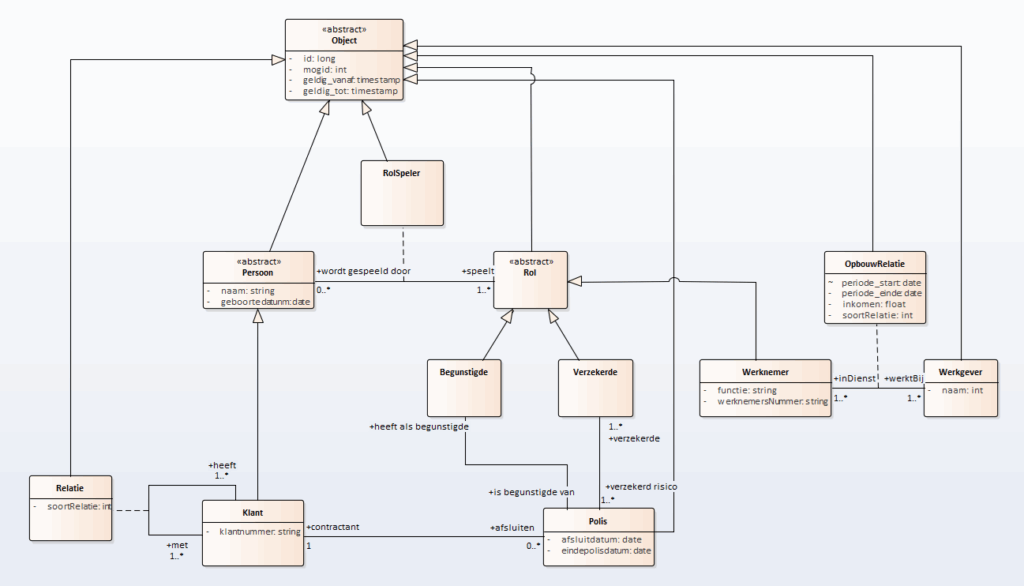
Schema-1
Definities
Metadata die niet direct zichtbaar is, maar wél aanwezig, bestaat uit de definities van entiteiten (classes) en attributen. Dankzij deze eenduidige definities zijn we in staat te interpreteren wat precies bedoeld wordt met een bepaald gegeven (class of attribuut).
Repository
Het is niet alleen belangrijk om metadata vast te leggen, maar ook om deze goed toegankelijk te maken. Gebruik hiervoor een tool die op de achtergrond werkt met een repository die via een API ontsloten is. Zo blijft de metadata altijd beschikbaar en raadpleegbaar, wat integraties met andere tooling mogelijk maakt. Ook buiten het beheertool om.